Research
Fluid-agent reinforcement learning
Most MARL work assumes that the set of agents is fixed. This is often the wrong abstraction. In many real systems, agents can be created, removed, merged, split, or reorganized: cells divide, organizations spin off teams, software agents spawn sub-agents, and collective systems change their own composition while solving a task.
My work on fluid-agent reinforcement learning studies what happens when population change becomes part of the decision process itself. Rather than treating the number of agents as a background constant, the agents must decide how to use population structure as a resource.
Core question: How should learning agents coordinate when they can change the set of decision-makers in the environment?
In this setting, spawning is not just an extra action. It changes the future action space, the reachable states, the credit-assignment problem, and sometimes even the strategic structure of the game. This leads to questions such as:
- When is it worth creating another agent?
- Which agent should create the new agent?
- What kind of agent should be created?
- How does population change affect equilibrium reasoning?
- Which MARL algorithms learn useful population-control behavior in practice?
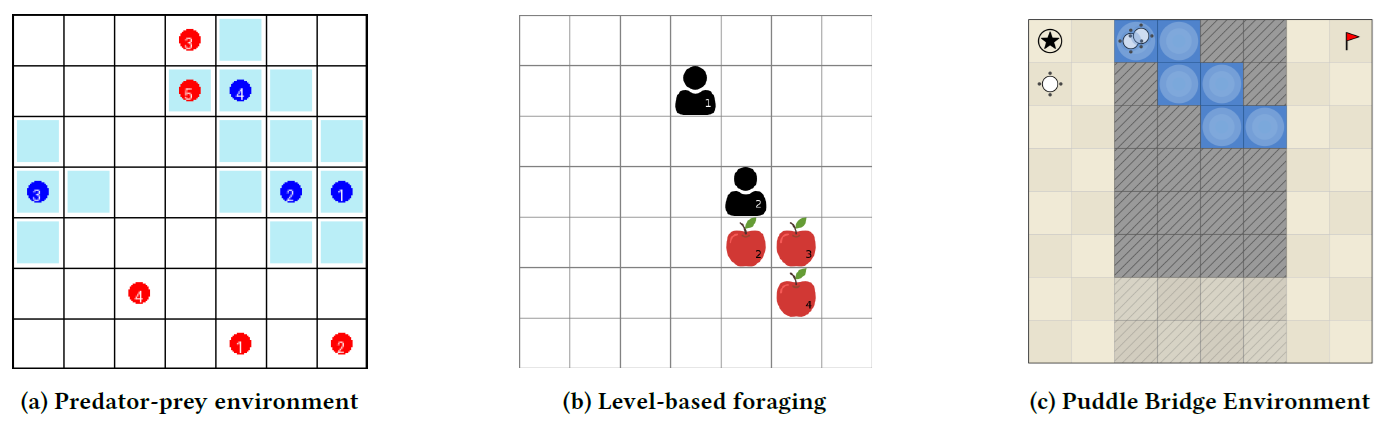
In my AAMAS 2026 paper, Fluid-Agent Reinforcement Learning, we formalize this setting using Partially Observable Fluid Stochastic Games and study equilibrium notions for fluid-agent games. We also introduce fluid variants of predator-prey and level-based foraging, along with PuddleBridge, an environment where spawning enables strategies that are not available to fixed-population agents.
Related paper: Fluid-Agent Reinforcement Learning, AAMAS 2026.

Environments for studying changing populations
A large part of this work is empirical: building environments where population change is not cosmetic, but necessary for solving the task well.
The environments I use are designed to test different aspects of fluidity:
Fluid predator-prey studies whether agents can adjust team size to task demand. When there are more prey, spawning can help; when prey are scarce, excessive spawning creates unnecessary cost.
Fluid level-based foraging studies whether agents can learn not only how many agents to create, but which kind. Since spawned agents inherit properties from their parent, the identity of the spawning agent matters.
PuddleBridge studies whether agents can switch between fluid and non-fluid strategies. When a gate is open, a single agent can solve the task; when it is closed, the agents must spawn and coordinate to cross the puddles. The interesting behavior is not simply “spawn more,” but conditionally using fluidity only when the environment demands it.
Design principle: population change should alter the solution space, not merely increase the number of bodies in the grid.
Model-based RL and analytic planning under uncertainty
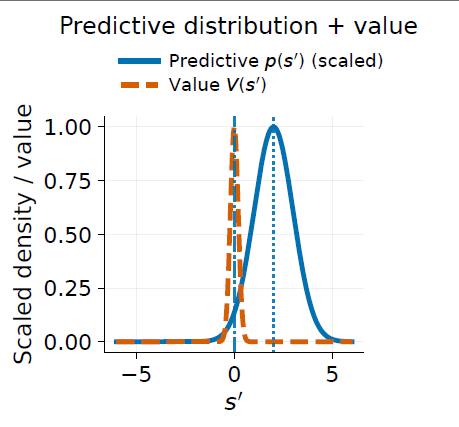
A second line of my work studies model-based reinforcement learning under stochastic dynamics. Model-based RL is attractive because it gives the agent an explicit predictive model, but planning with stochastic models often creates a difficult choice: either sample from the model, which introduces variance, or collapse the model to its mean, which discards uncertainty.
My work on moment-closure model-based RL asks whether we can avoid this trade-off by choosing the model and value representation so that the Bellman backup can be computed analytically.
Core idea: if the learned dynamics model and value function are moment-compatible, uncertainty can be propagated through Bellman backups deterministically rather than through Monte Carlo rollouts.
In this approach, a Gaussian dynamics model predicts both mean and covariance. A compatible value representation then allows the expected next-state value to be computed in closed form. This gives deterministic, uncertainty-aware targets that propagate predictive covariance without sampling or quadrature.
Related paper: Analytic Planning under Uncertainty via Moment Closure, UAI 2026.